|
|
 |
|
The Intelligence in Wikipedia Project
Overview
Berners-Lee's compelling vision of a Semantic Web is hindered by a
chicken-and-egg problem, which can be best solved by a bootstrapping
method, creating enough structured data to motivate the development
of applications. We believe that autonomously `Semantifying
Wikipedia' is the best way to solve the problem. We choose Wikipedia
as an initial data source, because it is comprehensive, not too large,
high-quality, and contains enough manually-derived structure to
bootstrap an autonomous, self-supervised process. Specifically,
Wikipedia contains infoboxes, taxonomic data, multi-lingual
correspondences, link structures, edit history, and other features
which greatly simplify extraction.
The Intelligence in Wikipedia Project aims to accelerate the
extraction of Wikipedia knowledge, e.g. with construction of
infoboxes, and link the resulting schemata together to form a
knowledge base of outstanding size. Not only will this `semantified
Wikipedia' be an even more valuable resource for AI, but it will
support Faceted browsing and simple forms of inference that may
increase the recall of question-answering systems.
Research Activities
- The Kylin System
Kylin is our original prototype for a self-supervised, machine
learning system which realizes our vision. Kylin looks for classes
of pages with similar infoboxes, determines common attributes,
creates training examples, learns CRF extractors, and runs them
on each page-creating new infoboxes and completing others.
Experiments show that the performance of Kylin is roughly comparative with
manual labelling in terms of precision and recall. On one domain,
it does even better.
-
Automatic Ontology Induction
The combined efforts of human volunteers have recently extracted
numerous facts fromWikipedia, storing them asmachine-harvestable
object-attribute-value triples inWikipedia infoboxes. Machine learning
systems, such as Kylin, use these infoboxes as training data,
accurately extracting even more semantic knowledge from natural
language text. But in order to realize the full power of this
information, it must be situated in a cleanly-structured
ontology. This paper introduces KOG, an autonomous system for refining
Wikipedia's infobox-class ontology towards this end. We cast the
problem of ontology refinement as a machine learning problem and solve
it using both SVMs and a more powerful joint-inference approach
expressed in Markov Logic Networks. We present experiments
demonstrating the superiority of the joint-inference approach and
evaluating other aspects of our system. Using these techniques, we
build a rich ontology, integrating Wikipedia's infobox-class schemata
with WordNet. We demonstrate how the resulting ontology may be used to
enhance Wikipedia with improved query processing and other
features.
-
Improved Recall with Shrinkage and Retraining
Not only is Wikipedia a comprehensive source of quality information,
it has been shown that it has several kinds of internal structure
(e.g., relational summaries known as infoboxes), which enable
self-supervised information extraction. While previous efforts
at extraction from Wikipedia achieve high precision and recall on
well-populated classes of articles, they fail in a larger number of
cases, largely because incomplete articles and infrequent use of infoboxes
lead to insufficient training data. We proposed two
novel techniques for increasing recall from Wikipedia's long tail
of sparse classes: (1) shrinkage over an automatically-learned subsumption
taxonomy by KOG, (2) a retraining technique for improving the
training data by mapping the contents of known Wikipedia infobox data to TextRunner. Our experiments compare design variations and show
that, used in concert, these techniques substantially increase recall while maintaining or increasing precision.
-
Completing Wikipedia Infoboxes by Extracting from the Web
The lack of redundancy of Wikipedia�s content makes it increasingly
more difficult to extract additional information. Facts that
are stated using uncommon or ambiguous sentence structures hide
from the extractors. In order to retrieve facts which can�t be
extracted from Wikipedia, we therefore turn to the broader Web and
apply extractors, which have been trained on Wikipedia articles, to
other relevant Web pages. An obvious benefit of this approach is
the ability to find new facts which are not contained in Wikipedia
at all.
The challenge for this approach - as one might expect - is maintaining
high precision. Since the extractors have been trained on
a very selective corpus, they are unlikely to discriminate irrelevant
information. For example, a Kylin extractor for a person�s birthdate
has been trained on a set of pages all of which have as their primary
subject that person�s life. Such extractors become inaccurate when
applied to a page which compares the lives of several people -
even if the person in question is one of those mentioned. In our work,
we show how tight filtering and re-weighting of extractions
allows increasing recall while maintaining high precision.
-
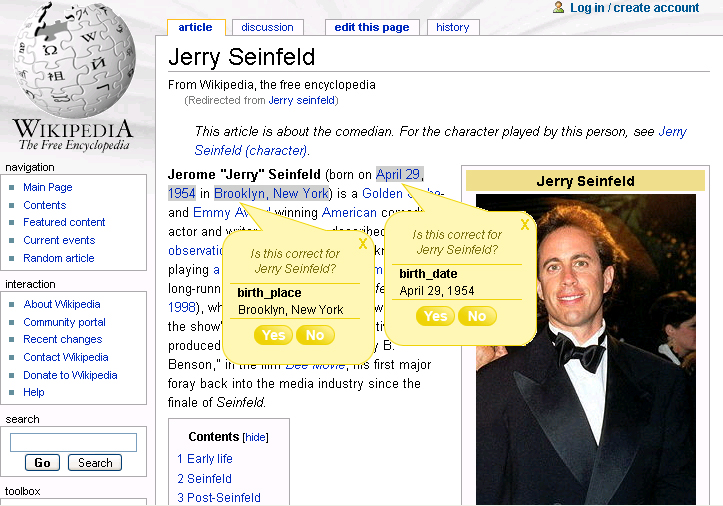
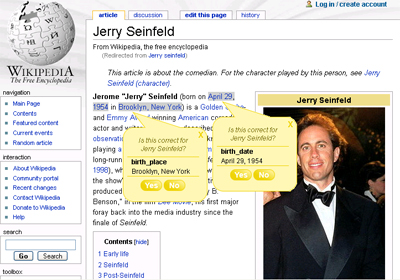 Mixed-Initiative Interfaces for Wikipedia Editors
Mixed-Initiative Interfaces for Wikipedia Editors
Despite improvements in precision, even advanced information extraction
techniques produce errors. Errors are not tolerated by Wikipedia's users
and editors, prohibiting the use of fully automatic systems. While human
feedback is often more accurate, it may require incentives to motivate
contribution and management to control spam and vandalism. We therefore
propose systems that tightly integrate human and machine feedback:
information extraction techniques generate candidate facts, and users
correct errors, improving training data and enabling a virtuous cycle. To
maximize the amount and quality of human feedback, our systems adapt to the
ecology of users by applying decision theory to select among extractions to
present to a user and to select among several interfaces: An interface for
casual users may ask for confirmation of a few facts on an article page,
whereas an interface for professional users might display a list of
extractions ranked by an active learning-based scoring technique.
Publications
-
- Raphael Hoffmann, Saleema Amershi, Kayur Patel, Fei Wu, James Fogarty, Daniel S. Weld.
Amplifying Community Content Creation Using Mixed-Initiative Information Extraction
In CHI 2009, Boston, USA, April 2009.
[pdf]
 Best Paper Nominee Best Paper Nominee
-
- Daniel S. Weld, Raphael Hoffmann, Fei Wu.
Using Wikipedia to Bootstrap Open Information Extraction
ACM SIGMOD Record, December 2008.
[pdf].
-
-
Etzioni, O. and Banko, M. and Soderland, S. and Weld, D. Open
Information Extraction from the Web, Communications of the ACM 51(12),
December 2008. [pdf]
-
- Stefan Schoenmackers, Oren Etzioni
and Daniel Weld Scaling Textual Inference to the Web, Proceedings of the
2008 Conference on Empirical Methods in Natural Language Processing
(EMNLP 2008), Honolulu, Hawaii, October 2008. [pdf]
-
- Daniel S. Weld, Fei Wu, Eytan Adar, Saleema Amershi, James Fogarty, Raphael Hoffmann, Kayur Patel, Michael Skinner.
Intelligence in Wikipedia
In the 23rd AAAI Conference, (AAAI-08), Chicago, USA, July, 2008.
[pdf]
-
- Fei Wu, Raphael Hoffmann, Daniel S. Weld.
Information Extraction from Wikipedia: Moving Down the Long
Tail In the 14th International Conference on Knowledge
Discovery & Data Mining (KDD-08), Las Vegas, USA, August, 2008
[pdf]
-
- Fei Wu, Daniel S. Weld.
Automatically Refining the Wikipedia Infobox Ontology In the 17th International World Wide Web Conference, (WWW-08), Beijing, China, April, 2008
[pdf]
Best Student Paper Nominee
-
- Fei Wu, Daniel S. Weld.
Autonomously Semantifying Wikipedia In the Sixteenth Conference on Information and Knowledge Management (CIKM-07), Lisbon, Portugal, November, 2007.
[pdf]
Awarded Best Paper
-
Other Wikipedia-Related Work at UW
- Open information extraction using TextRunner [demo]
- Borning, A., B. Friedman, J. Davis, B. Gill, P. Kahn, T. Kriplean, and P. Lin.
Laying the Foundations for Public Participation and Value
Advocacy: Interaction Design for a Large-Scale Scale Urban Simulation (To appear) Proceedings of the 9th Annual International Conference on
Digital Government Research (DGO '08).
- Beschastnikh, I., T. Kriplean, and D.W. McDonald.
Wikipedian Self-Governance in Action: Motivating the Policy Lens Proceedings of the 2008
AAAI International Conference on Weblogs and Social Media (ICWSM '08).
-
Kriplean, T., Beschastnikh, I., D.W. McDonald, and S. Golder.
Community, Consensus, Coercion, Control: CS*W or How Policy Mediates Mass
Participation Proceedings of the 2007 ACM Conference on Supporting Group Work (GROUP '07).
Affiliates

|
Turing Center
The Turing Center is a multidisciplinary research center at the University of Washington, investigating problems at the crossroads of natural language processing, data mining, Web search, and the Semantic Web.
|

|
DUB
DUB is an alliance of faculty and students across the University of Washington exploring Human-Computer Interaction and Design.
|
|
 CSE Home
CSE Home